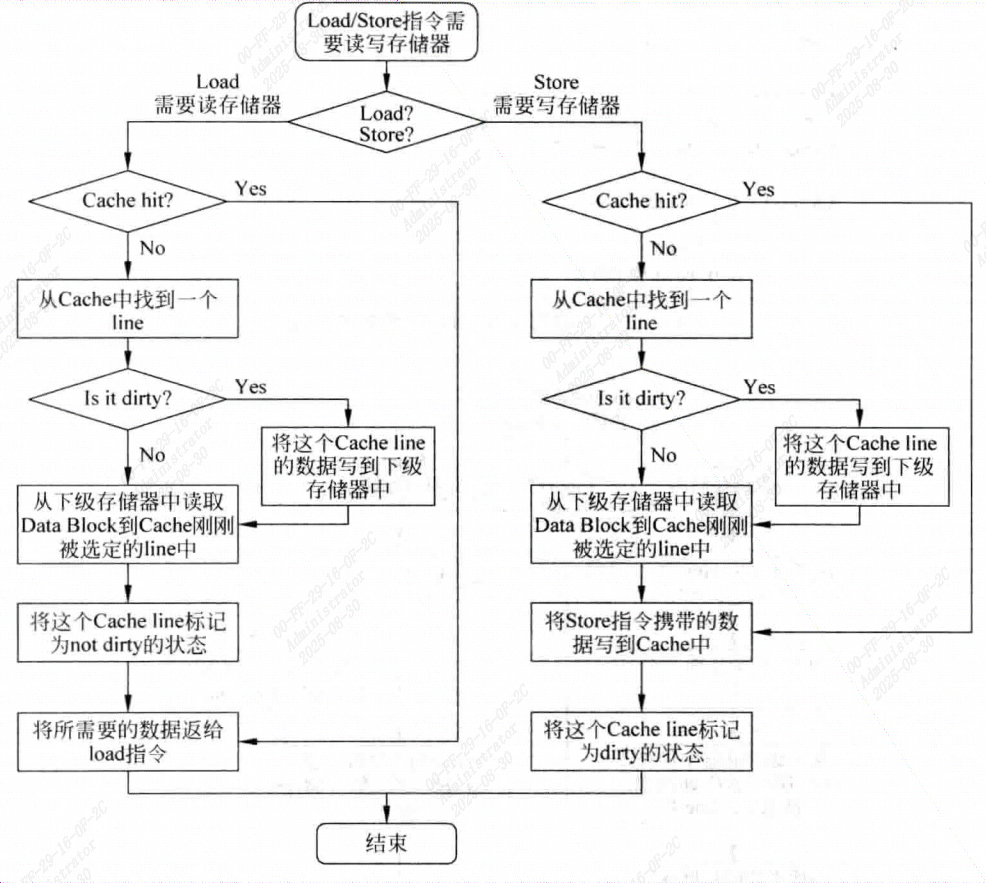
超标量处理器设计_Cache
Cache
L1 Cache L2 Cache
l1c快,每个核私有的。l2c全,可能是核之间共享的(现代也可能是l3c共享)
ICache:需要每周期能读多条指令,延迟时间即使很大,也不会造成处理器性能下降
DCache:需要支持每周期有多条load store指令访问,需要多端口设计
几个概念
cache主要由两部分组成,Tag部分和Data部分,一个Tag和它对应的所有数据组成的一行称为一个Cache line,数据部分
称为数据块Cache data block/Cache block/Data block,若一个数据可以存储在擦车中的多个地方,则这些被同一地址找到的多个Cache Line称为Cache Set。
Cache的实现方式
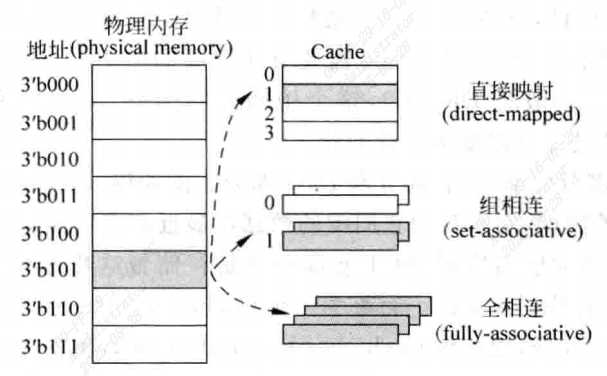
直接映射 direct-mapped Cache
对物理内存中的一个数据来说,如果Cache中只有一个地方可以容纳它,则为直接映射。
组相联set-associative Cache
如果Cache中有多个地方可以放置这个数据,则为组相联。
全相联fully-associative Cache
如果Cache中任何一个地方都可以放置这个数据,则为全相联。
[!NOTE]
TLB的Victim Cache多采用全相联,而普通的I-Cache和D-Cache采用组相联
Cache的缺失
Cache容量有限,只能保存近期处理器使用过的内容,并且很多情况下要找的指令或数据不在Cache中,即为Cache缺失 Cache miss:
Compulsory
Cache只是缓存以前访问过的内容,故第一次被访问的指令/数据不在Cache中,不过可以采取预取(prefetching)的方法来降低这种缺失发生率。
Capcity
容量造成Cache缺失发生率。
Conflict
多个数据映射到Cache中同一个位置的情况导致的缺失,可以使用Victim Cache来解决。
这三种影响Cache缺失的条件又叫3C定理。
1.Cache的一般设计
Cache组成方式
直接映射
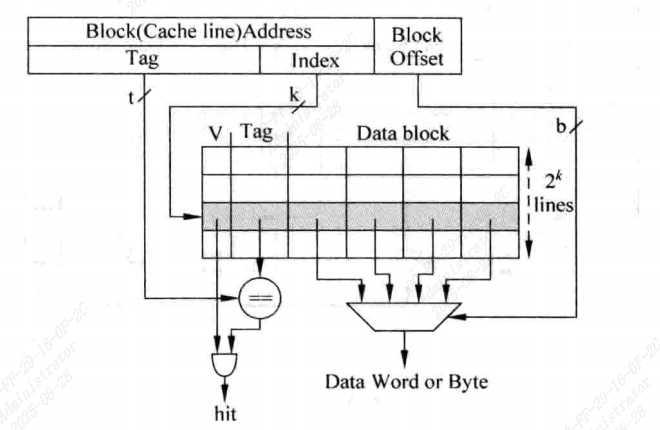
最容易实现,处理器访问地址存储器地址被分为三个部分:
| Tag | Index | Block Offset |
|---|
- Index来从Cache中找到一个对应的Cache line。
- 但是所有Index相同的地址都会寻址到这个Cache line,因此需要Tag来和地址中的Tag进行比较,只有当他们相等时,才说明这个Cache line正确。
- 在一个Cache line中有很多数据,通过Block Offset部分可以找到需要的数据。
- Cache line中还有一个有效位Valid,只有在之前被访问过的存储器地址,数据才会存在于对应Cache line中,相应的,有效位也会被置1。
[!NOTE]
直接映射结构实现上是最简单的,不需要替换算法,但效率最低
组相联
为了解决直接相联结构Cache不足而提出的, 存储器中的一个数据可以放在多个Cache line中
[!NOTE]
对应一个组相联结构的Cache来说,如果一个数据可以放在n个位置,则为n路组相联
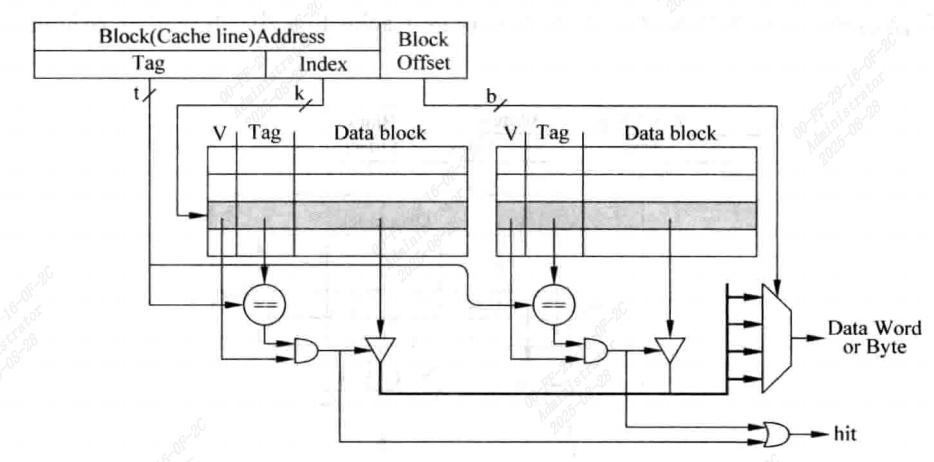
- index部分对Cache进行寻址,可以获得x个Cache line(设x为组相联数), 然后通过Tag对比来确定结果
如果index索引到的所有cache line,都与tag不匹配,则为Cache缺失
因为要从多个Cache line中选择,所以相比直接映射,延迟更大(有时需要用到流水线),但是可以显著减少Cache确实的概率
这种结构是使用最广泛的
组相联的Tag和Data是分开存放的,分别为Tag SRAM和Data SRAM,可以同时访问
- 并行访问Tag和Data:
- 串行访问Tag和Data:先访问Tag后访问Data
[!NOTE]
一般将选择字节的过程称为数据对齐
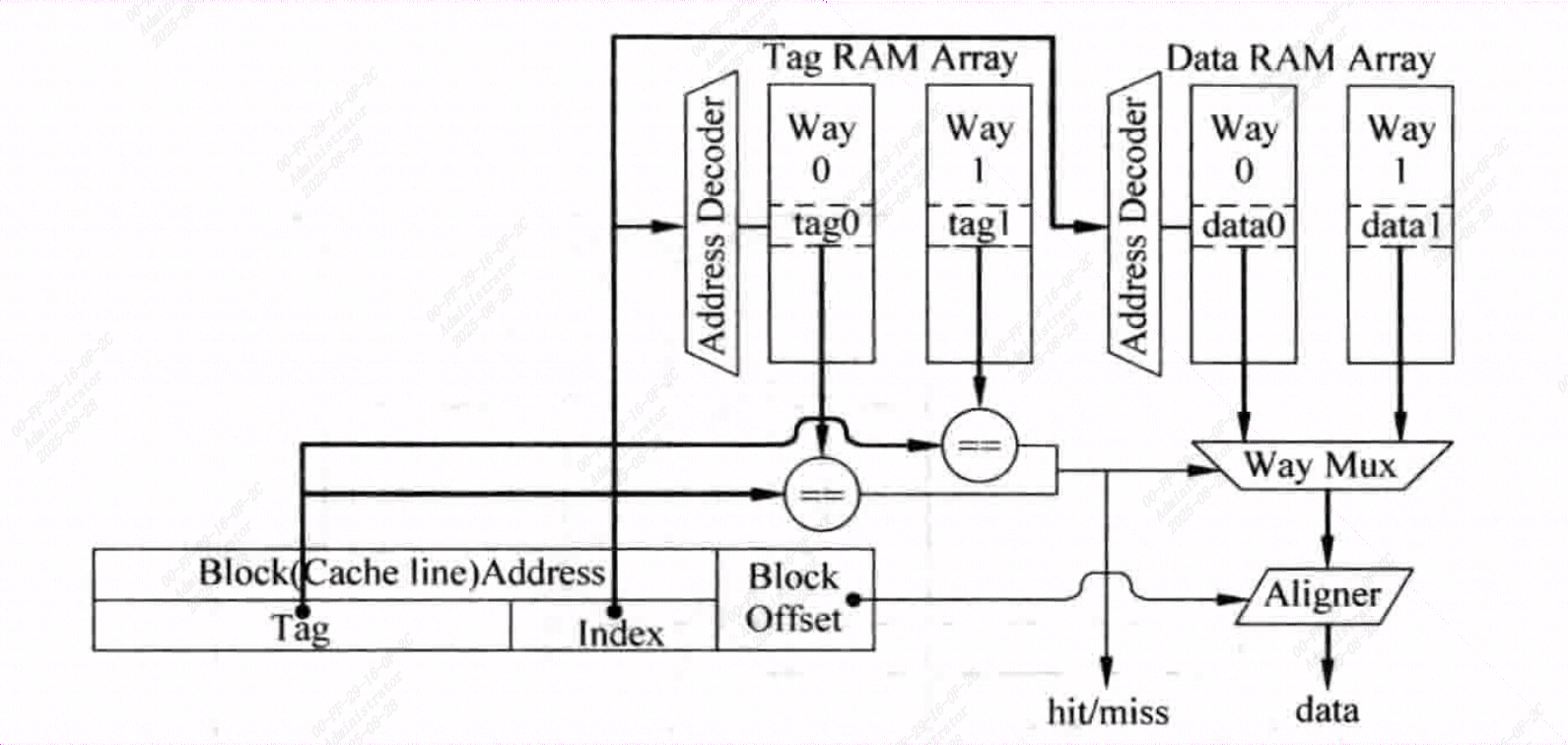
Cache访问一般都是处理器中的关键路径,图中这个结构实现了单周期的访问操作,延时很长,组要对Cache访问进行流水线划分:
- 指令Cache进行流水线对性能不影响,仍可实现每周期读取指令
- 但数据Cache如果进行流水线切分就会增加Load指令的延迟
下图是并行访问的流水线结构,通过这种方式可以降低处理器周期实践。
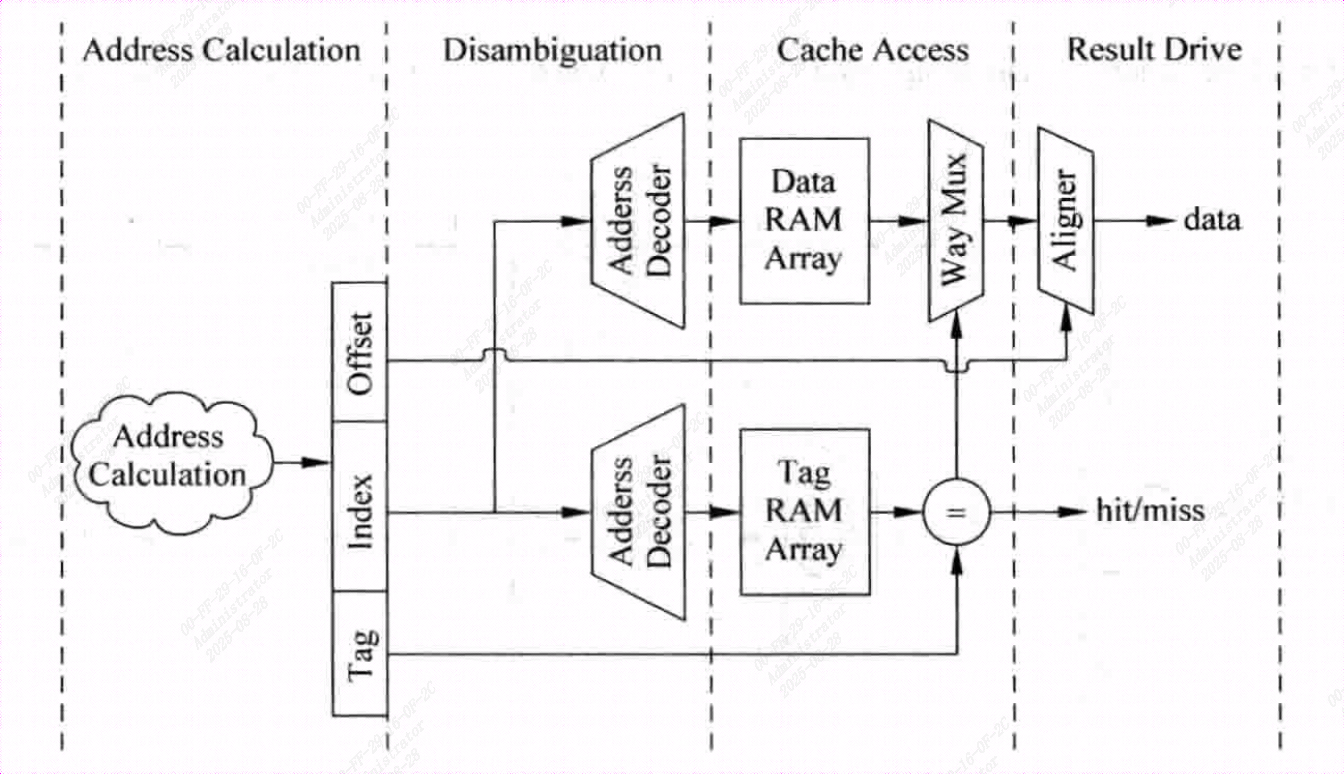
而对于串行访问,可以先访问Tag SRAM,这样就可以先知道数据部分中哪一路数据是需要访问的,就不需要Way Mux多路选择器了 ,但是这样就增加了一个周期,会增加load指令的延迟
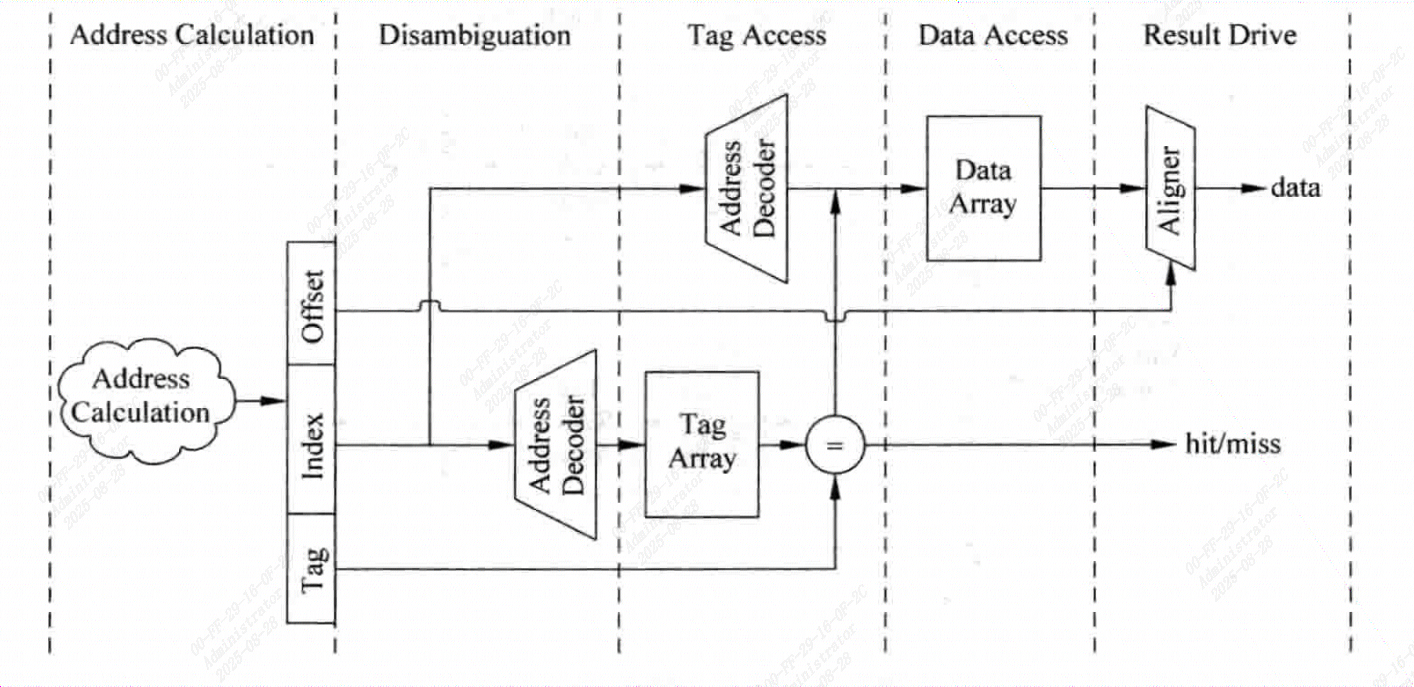
两种方式各有优劣
并行访问时会有较低的时钟频率和较大的功耗,但是cache访问缩短了一个周期
在超标量处理器中,当Cache的访问处于关键路径上时,可以使用串行访问来提高时钟频率
在普通处理器中,无法对指令进行调度,因此如果增加一个周期,就很可能会导致处理器性能的降低,因此使用并行
全相联
一个存储器地址对应的数据可以放置在任意一个Cache line中,存储器地址中没有index部分,而是直接在Cache中进行Tag比较,找到比较结果相等的那个Cache line。相当于直接使用存储器内容来寻址。
[!NOTE]
这就是内容寻址的存储器,CAM
实际处理器在使用全相联结构的Cache时都是使用CAM来存储Tag值,使用普通RAM来存储数据的,在CAM中某一行被寻址到后,SRAM中对应的行也将会被找到。
全相联结构有着最大的灵活度,因此缺失率是最低的,但是延迟最大。
Cache写入
[!NOTE]
自修改self-modifying:将要改写的指令作为数据写入到D-Cache中,然后将D-Cache中的内容写到下级存储器中(例如L2,必须是指令和数据Cache共享的)并将I-Cache中所有指令置为无效,如此处理器再次执行时,就会使用被修改的指令了。
写回与写通
在执行store指令时,如果只是向D-Cache中写入数据,并不改变它对应的下级存储器中的数据,那么就会导致D-Cache和它对应的下级存储器中的数据不一致(non-consistent),要解决这个问题,有写通和写回两种方法
- 写通
数据在写入到D-Cache的同时,也写到它的下级存储器中
但是下级存储器的访问实践通常较长,而且store指令出现的频率高,因此处理器执行效率不高。
- 写回
数据写入到D-Cache的同时,不写入到下级存储器,而是对写入的Cache line做一个记号(dirty),在当前Cache line被替换时,才将它写入到下级存储器中。
这样会减少写慢速存储器的频率,但是会给存储器一致性管理来负担。
写缺失
当对Cache写入时,发现这个地址不在Cache中,这就发生了写缺失
写缺失的解决方法包括Non-Write-Allocate,Write Allocate
- Non-Write-Allocate
直接将数据写入到下级存储器中,而不是写入到D-Cache中
- Write Allocate
在发生缺失时,会首先从下级存储器中将这个发生缺失的地址对应的整个数据块取出来,将要写入到D-Cache中的数据合并到这个数据块中,然后再将这个被修改过的数据块写到D-Cache中。
[!NOTE]
在发生写缺失时,为什么不直接从D-Cache中找到一个line,将要写入的信息直接写到这个line中,同时也将它写到下级寄存器中呢?为啥还要先从下级存储器中将对应数据块读出来并写到D-Cache中?
因为在处理器中,写入D-Cache最多写入一个字,如果直接从D-Cache中找到一个line来存储这个需要写入的数据并将这个line标记为dirty状态,,会导致这个line中,数据块中的其他部分和下级存储器中对应地址数据不一致,而此时D-Cache中这些数据是无效的,如果这个cache line由于被替换而写回到下级存储器中时,就会使下级存储器中的正确数据被篡改。(这个地方看的不是很明白)
- 对D-Cache来说,一般情况下,写通要配合Non_Write Allocate一起使用,都是直接将数据更新到下级存储器中,如下图。
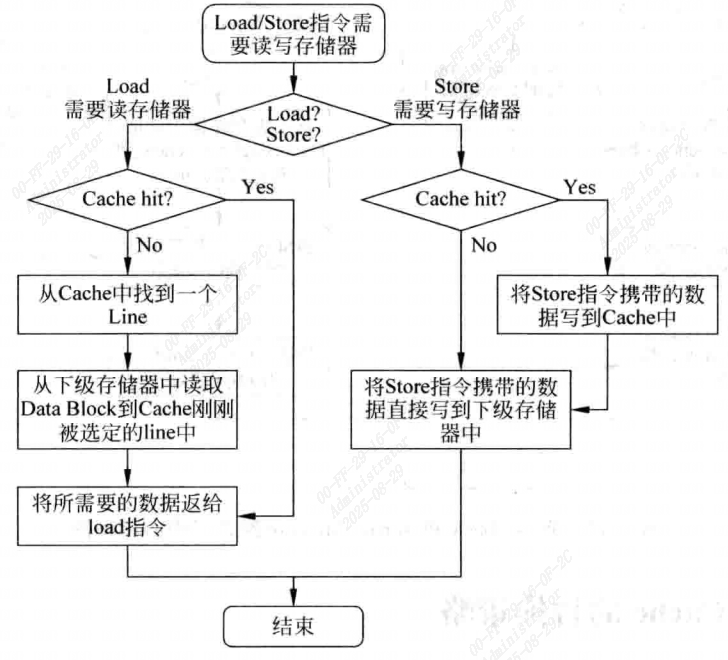
- 同样写回和Write Allocate也是配合在一起的
Cache 替换策略
- 近期最少使用法(Least Recently Used,LRU)
选择最近被使用次数最少的Cache line,这需要为每个Cache line都设置一个年龄age,每次当一个一个Cache line被访问时,它的年龄部分就会增加,(或其他Cache line的年龄值减少), 这样在进行替换时,年龄最小的那个Cache line就是被使用次数最少的。
举个例子,一个两路组相联结构,每个way就只需要一位age就可以吗,当一个way被使用时,这个way的年龄被置1,另一个way的年龄部分被置零。 但随着Cache相关度的增加,即way个数的增加,要实现这种LRU算法就很昂贵了,因此在相关度很高的cache中,都是使用伪LRU算法, 将所有way进行分组,每一组使用一个1位的年龄部分。
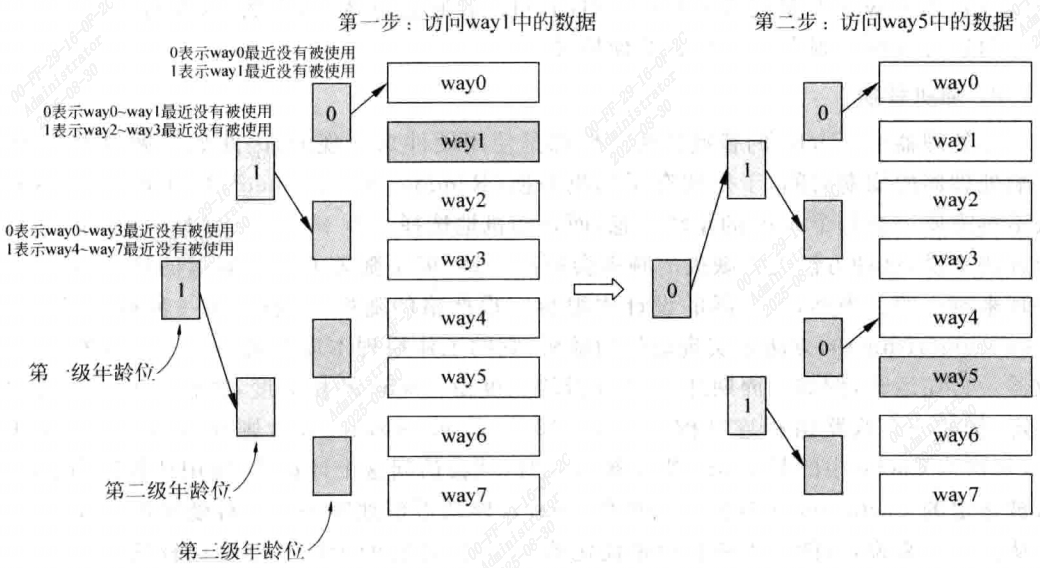
- 随机替换
Cache的替换算法一般是使用硬件来实现的, 因此如果做的很复杂,会影响处理器的周期时间,于是就有了随即替换。
这种方法不需要记录每个way的年龄信息,而是随机选择一个way进行替换。相比LRU,这种方法发生缺失的频率会更高,但随着Cache容量增大,这个差距越来越小。
不过在现实中很难实现严格的随机,一般采用一种时钟算法(clock algorithm)的方法来实现近似的随机。
2.提高Cache的性能
采用更复杂的方法来提高Cache的性能,包括写缓存、流水线、多级结构、Victim Cache、和预取等
在超标量处理器中,还有其他方法来提高Cache性能,如非阻塞Cache、关键字优先和提前开始等。
写缓存
当D-Cache发生缺失时,需要从下一级存储器中读取数据写入到一个选定的Cache line中,如果这个line是脏的状态,需要先把这个line中的数据写回到下级存储器中,然后才能读取下级存储器而得到缺失的数据,而下级存储器的访问时间都比较长,这种串行的过程导致D-Cache发生缺失的处理时间变得很长,因此可以使用写缓存write buffer
脏状态的Cache line会首先放到写缓存中,等到下级存储器有空闲的时候,才会将写缓存中的数据写到下级存储器中。
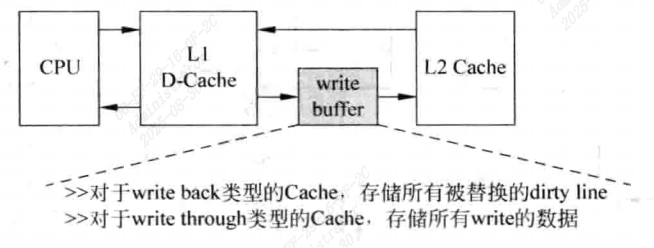
对于写回类型的D-Cache来说,当一个脏状态的Cache line被替换时,这个line的数据会首先放到写缓存中,然后就可以从下级存储器中读数据了,而写缓存中的数据会择机写入到下级存储器中。
对于写通类型来说,采用写缓存后,每当数据写道D-Cache的同时,并不会同时也写到下级存储器中,而是将其放到写缓存中。
[!IMPORTANT]
写通类型Cache由于便于进行存储器一致性的管理,所以在多核处理器中,L1 Cache会经常采用这种结构。
写缓存对写通类型的Cache尤为重要。
[!WARNING]
加入写缓存后,会增加系统设计的复杂度,例如当读取D-Cache发生缺失时,不仅需要从下级存储器中查找这个数据,还需要在写缓存中也查找。
流水线
对于读D-Cache来说,由于Tag SRAM和Data SRAM可以在同时进行读取,所以在处理器的周期不是很严格的时候,可以在一个周期完成读写操作。
但对于写D-Cache来说,读取Tag SRAM和Data SRAM操作只能串行完成,在主频高的处理器中,这些操作很难一个周期内完成,这就需要对D-Cache写操作采用流水线结构。
流水线划分方式有很多种,典型的就是将Tag SRAM的读取和比较放在一个周期,写Data SRAM放在下一个周期。
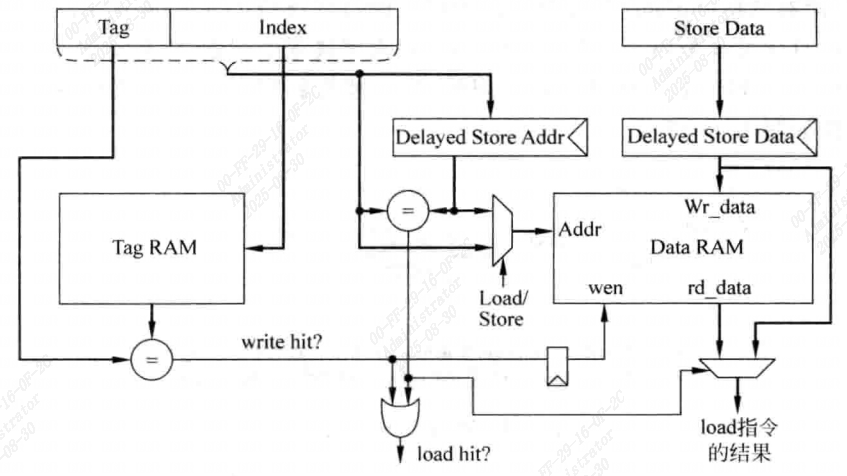
在这种机制中,load指令在D-Cache命中的情况下,可以在一个周期内完成,store指令两周期。
需要注意的是,当执行load指令时,它要的数据可能正好在store指令的流水线寄存器中,而不是来自Data SRAM,因此需要一种机制,能够检测到这种情况。这需要将load指令所携带的地址和store指令的流水线寄存器进行比较,如果相等,则将store指令的数据作为load指令的结果。
多级结构
存储器无法实现容量大同时速度又很快,所以使用多级结构来使处理器看起来使用了一个容量大同时速度快的存储器。

L1 Cache容量很小,能够跟处理器内核保持同样的速度等级,L2 Cache访问通常需要几个时钟周期,但容量大一些。一些高阶的处理器还会有片上的L3 Cache。
在一般处理器中L2 Cache会使用写回方式,但对于L1 Cache来说,写通实现方式也是可以接受的。
对于多级结构Cache,需要了解两个概念,Inclusive和Exclusive:
- Inclusive:如果L2 Cache 包括了L1 Cache中所有的内容,则称L2 Cache是Inclusive的。
- Exclusive:如果L2 Cache和L1 Cache中的内容互不相同,则L2 Cache是Exclusive的
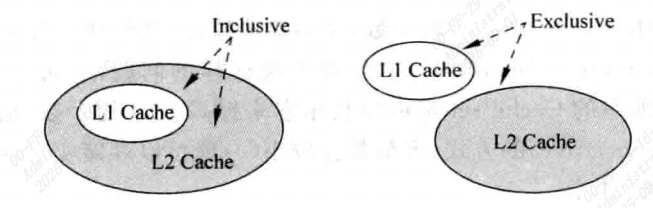
Inclusive是比较浪费硬件资源的,因为将一份数据保存在两个地方。但是好处是可以直接将数据写道L1 Cache中,虽然此时L1中的数据被覆盖,但是L2中存在这个数据的备份,但被覆盖的line不能是dirty的。
并且Inclusive也简化了一致性管理。
[!NOTE]
现代的大多数处理器都采用了Inclusive类型的Cache。
Victim Cache
有时候Cache中被踢出的数据可能马上又要被使用,例如在一个2 way的cache中,有三个频繁使用的数据位于同一个cache set中。这样需要频繁的踢出-写入。cache始终无法命中数据。
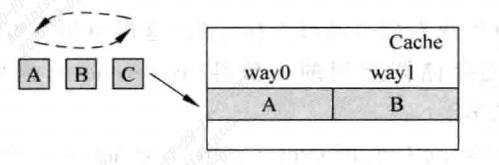
VC可以存储最近被踢出Cache的数据,通常VC采用全相联方式,容量都比较小 4~16个。

VC本质上相当于增加Cache中way的个数,降低Cache的缺失率。
一般情况下,Cache和VC存在互斥关系,不会包含同样的数据,处理器内核可以同时读取,如果在Cache中没有找到想要的数据但在VC中找到了,跟Cache命中效果是一样的,同时VC的数据被写到cache中,cache中被替换的数据写到VC中。
[!NOTE]
现代大多数处理器都采用了VC
还有一种类似的设计思路称为Filter Cache。当一个数据第一次被使用时,它不会马上被放到cache中,等到这个数据再次被使用时,才会被搬移到cache。这样可以防止偶然被使用的数据占据Cache。
预取
当处理器第一次访问一条指令或数据时,这个指令或数据肯定不会在cache中。可以采取预取来缓解这个问题。
- 硬件预取
对于指令来说,猜测后续会执行什么指令是相对容易的,因为程序是串行执行的,只需要在访问ICache中的一个数据块的时候,将它后面的数据块也去出来放到ICache就可以了。
但程序中可能存在分支指令,所以这种猜测也可能出错,使不被使用的指令进入了ICache,这样不光降低了Cache的可用容量,还占用了本来可能有用的指令,这称为“Cache 污染”

硬件预取如图所示,当ICache发生缺失时,除了将需要的数据块从L2中取出来放到L1中,还会将下一个数据块也取出来,放到Stream Buffer中。
如果在ICache中发生了缺失,但是在Stream Buffer中找到了想要的指令,这时除了使用Stream Buffer中读取的指令外,还会将其中对应的数据块搬移到ICache中,同时继续从L2中取下一个数据块放到Stream Buffer中。
这样当程序中没有分支指令时,会一直正常工作,并降低Cache缺失率,但遇到分支指令会导致Stream Buffer中的数据无效。
[!NOTE]
对于DCache来说,顾虑更加难以捕捉,一般当访问DCache发生缺失时,除了将所需的数据块从下级存储器中取出来之外,还需要将下一个数据块也读取出来。
- 软件预取
在程序编译阶段,编译器就可以对程序进行分析,从而知道哪些数据需要进行预取。如果在指令集中设有预取指令,则编译器就可以直接控制程序进行预取。
[!NOTE]
软件预取有一个前提,就是预取时机,如果预取太晚,则需要的时候还没有取出来,预取就没意义。如果太早就可能踢掉DCache中一些本来有用的数据,造成污染。
使用软件预取指令时,处理器要能够继续指令,也就是继续从DCache中读取数据,这就要求DCache时非阻塞结构的。
在是西安虚拟存储器Virtual Memory的系统中,预取指令可能会引起一些异常,如发生Page Fault,虚拟地址错误或者保护违例等。
有两种处理方式:
- 处理错误的预取指令
- 不处理错误的预取指令,此时发生异常的预取指令就会变成一条空指令
3.多端口Cache
在超标量处理器中,为提高性能,处理器需要能在每周期同时执行多条load/store指令,这需要一个多端口的DCache。
[!NOTE]
在超标量处理器中,有很多部件都是多端口结构:寄存器堆,发射队列,重排序缓存等。但这些部件容量不大,所以及时采用多端口结构,也不会对芯片面积和速度产生太大负面影响。
但Dcache容量很大,因此需要采用一些方法来解决这个问题:
True Mulit-port
在现实当中不可能对Cache直接采用多端口的设计。
这种方法真的使用一个多端口的SRAM来实现多端口的Cache。以双端口为例,所有的Cache中的控制通路和数据通路都要进行复制,这就表示他有两套地址解码器Address Decoder,两个多路选择器Way Mux,比较器数量也增加一倍,并且要有两个对齐器。
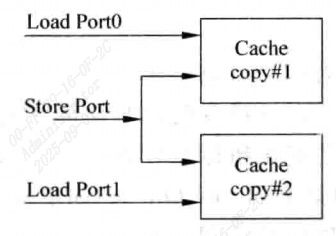
Mulitple Cache Copies
这种方法将Tag SRAM和Data SRAM进行复制,如图所示。
这种方式和上一种本质上时是一样的,但是通过将Cache复制,SRAM不需要再使用多端口结构,几乎可以消除对处理器周期的影响,但是浪费了很多的面积。而且需要保持两个Cache之间的同步。
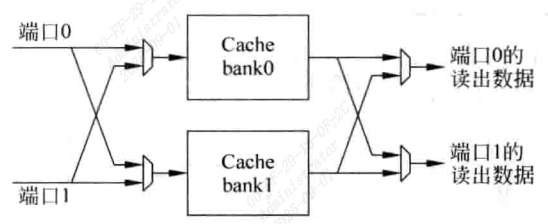
Multi-banking
将cache分为很多小的bank,每个bank都只有一个端口。
[!NOTE]
这种方式是现实中处理器最广泛使用的方法
如果在一个周期之内,若Cache的多个端口上的访问地址位于不同bank之中,则不会有任何问题。
只有当两个或者多个端口的地址位于同一个bank之中,才会引起冲突bank conflict。
使用这种方法,一个双端口的Cache仍旧需要两个地址解码器,两个多路选择器,两套比较器和两个对齐器,而Data SRAM就不需要多端口结构了。这样提高了速度而且在一定程度上节省了面积。
但由于需要判断Cache的每个端口是不是命中,所以对于Tag SRAM来说,仍需要提供多个端口同时读取的功能,也就是采用多端口SRAM来实现,或者采用将但端口SRAM进行复制的方法。
如图所示,只有在两个端口都访问一个bank时,才会产生冲突,在当前周期只能对一个端口进行响应。
[!TIP]
影响多端口Cache性能的一个关键因素就是bank冲突,可以采用更多的bank来缓解这个问题,使bank冲突发生概率尽可能降低。
4.超标量处理器的取指令
如果一个超标量处理器每周期可以同时解码四条指令,这个处理器就称为4-way的超标量处理器。
[!IMPORTANT]
对于一个n-way的超标量处理器来说,它给出一个取指令的地址后,I-Cache应能够至少送出n条指令,称这n条指令为一组(fetch group)
ICache如何能实现这个功能,最简单的方法使使数据块的大小为n个子,每周期全部输出

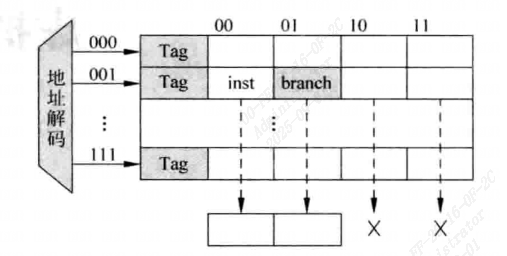
如图所示,如果处理器送出的取指令地址使n字对齐的,就可以实现每周期从ICache中读取n条指令的功能,在数据块部分需要n个32位的SRAM,当I-Cache命中时,这些SRAM会同时进行输出,不过这是理想的情况,实际情况下由于存在跳转指令,处理器送出的取指令地址不可能是n字对齐的
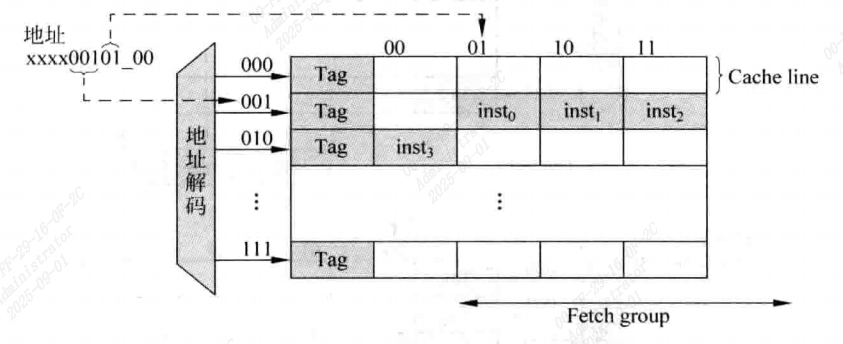
如下图所示,取指令的地址不是四字对齐,一个组中的指令就可能落在两个Cache line中,但对于Cache来说,每周期只能够访问一个Cache line,这会导致在一个周期内无法取出四条指令。图中这种情况就只能取出三条指令。这就会导致后续的流水线无法得到充足的指令,使部分资源空置。
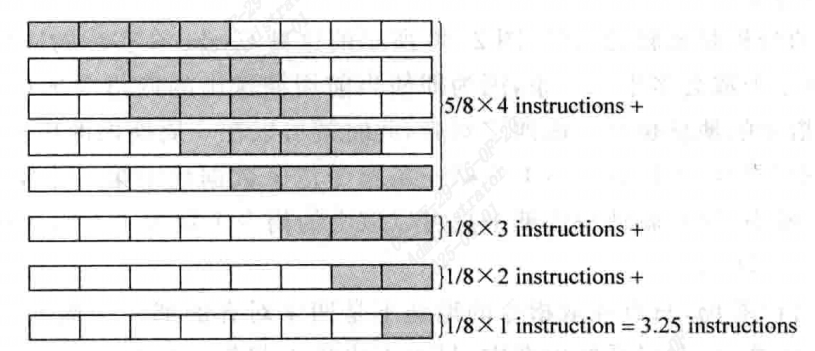
假设在取指令的组中第一条指令位置是随机的,每周期能够取出的指令个数是:
$$
\frac{1}{4} \times 4 + \frac{1}{4} \times 3 + \frac{1}{4} \times 2 + \frac{1}{4} \times 1 = 2.5
$$
这对于4way的超标量处理器是不够的,但是对于2way的处理器来说,就够用了。
这种分析是悲观的,在实际应用中每周期平均可以取出多于2.5条的指令,因为即使当前周期送出的取指令地址不是四字对齐的,下个周期取指令的地址也会变成四字对齐。
[!CAUTION]
指令组中第一条指令位于数据块中第一个字的概率是要大于在其他位置的概率。
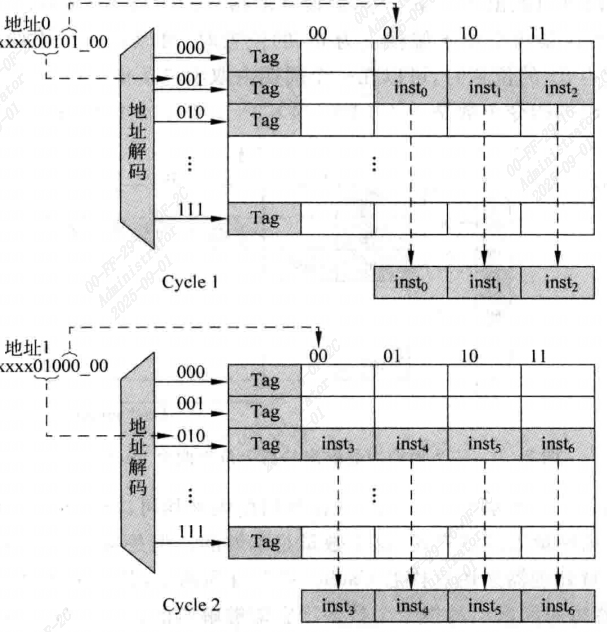
即使取指令的地址没有四字对齐,也有一些方法能够在一周期内读取四条指令。
最简单的就是使数据块变大,比如增大到8个,只要取指令地址不是落在最后三个字上,就可以在每个周期内读取4条指令。
但这种方法也有问题,在Cache容量一定的情况下,这种方法使Cache set的数量减少,会增加Cache的缺失率,因此不一定使性能提升。
[!WARNING]
如果每个数据块大小是八个字,也就需要使用八个32位的SRAM来实现这个Cache。在实际版图设计中,每块SRAM周围都需要摆放一圈保护电路,若SRAM个数过多,会使保护电路占用过多面积。而且要从八个字中选出四个字也是浪费亮度,需要大量布线资源和多路选择器,故在实际当中仍会使用四个SRAM来实现一个大小位八个字的数据块。
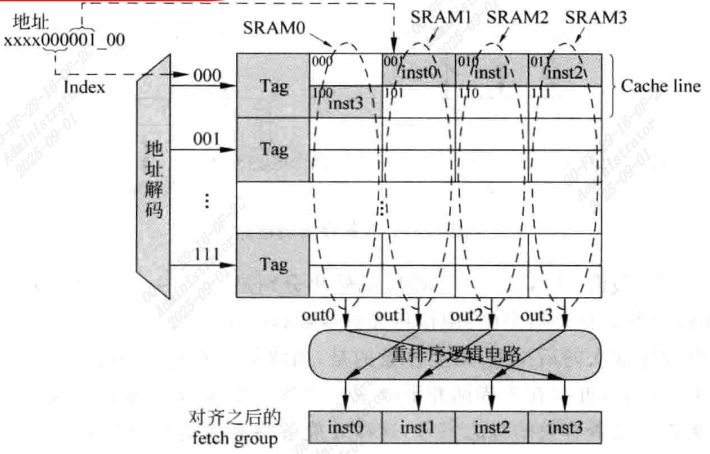
如上图所示的Cache中,一个Cache line占用的八个字实际上占据了SRAM的两行,因此共使用了四个32位的SRAM。每次Cache命中时,每个SRAM的两行数据都是有效的。
但需要注意,这时候四个SRAM的输出并不是按照指令原始顺序进行排列的,例如图中SRAM0就应在最后,因此需要一段重排序的逻辑电路对四个SRAM的指令进行重排序。
这种结构的Cache需要两个额外的控制电路:
- 产生每个SRAM的都地址
- 将四个SRAM输出的内容进行重排序,重排序逻辑电路如图
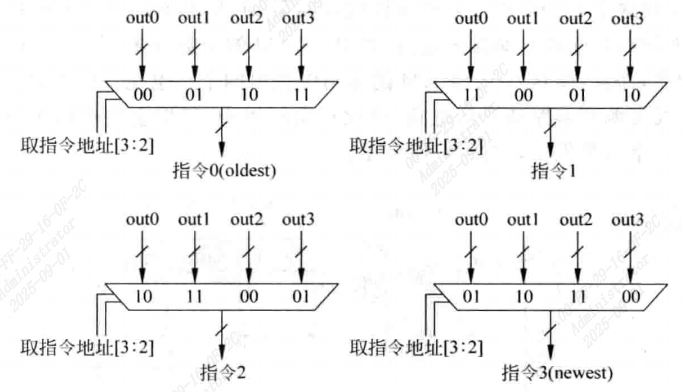
[!NOTE]
如果取指地址指向了Cache line中的后三个字,此时本周期不能输出四条指令,所以在重排序逻辑电路中还需要加入指示每条指令是否有效的标志信号
如果在处理器中有分支预测功能,则上述取指令的过程还需要更复杂一些